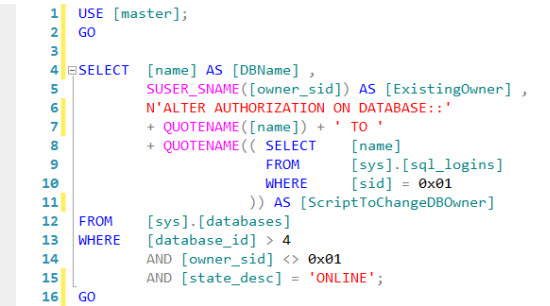
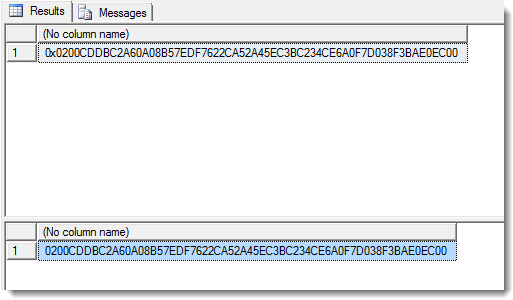
Problem
Recently, when I tried to install SQL Server 2017 (mssql-server package) in Ubuntu 18.04, I encountered the error below:

The command that I used to install the mssql-server package is the following:
sudo apt-get install -y mssql-server
Reason for error
This error suggested that the mssql-server package could not acquire the dpkg frontend lock (/var/lib/dpkg/lock-frontend) because another process already locked it.
Solution
To solve the problem, I first ran the following command to find the id of the process (PID) that already acquired a lock on dpkg frontend (/var/lib/dpkg/lock-frontend):
lsof /var/lib/dpkg/lock-frontend
*Note: Lsof lists on its standard output file information about files opened by processes.
Next, I ran the following sudo kill -9 command to kill that process:
sudo kill -9 122
*Note: Here 122 is the process identifier of the process that has the lock on dpkg frontend.
Then, I ran the following two commands on Ubuntu terminal to remove the lock and reconfigure dpkg:
sudo rm /var/lib/dpkg/lock-frontend sudo dpkg --configure -a
Finally, I ran the following install SQL Server again to install SQL Server:
sudo apt-get install -y mssql-server
This time, the mssql-server package installation completed successfully. Here is the output of the installation package:
basitfarooq@ubuntu:~$ sudo apt-get install -y mssql-server Reading package lists... Done Building dependency tree Reading state information... Done The following packages were automatically installed and are no longer required: linux-headers-4.18.0-15 linux-headers-4.18.0-15-generic linux-image-4.18.0-15-generic linux-modules-4.18.0-15-generic linux-modules-extra-4.18.0-15-generic Use 'sudo apt autoremove' to remove them. The following additional packages will be installed: gawk libc++1 libc++abi1 libjemalloc1 libpython-stdlib libsasl2-modules-gssapi-mit libsigsegv2 libsss-nss-idmap0 python python-minimal python2.7 python2.7-minimal Suggested packages: gawk-doc clang python-doc python-tk python2.7-doc binfmt-support The following NEW packages will be installed: gawk libc++1 libc++abi1 libjemalloc1 libpython-stdlib libsasl2-modules-gssapi-mit libsigsegv2 libsss-nss-idmap0 mssql-server python python-minimal python2.7 python2.7-minimal 0 upgraded, 13 newly installed, 0 to remove and 124 not upgraded. Need to get 180 MB of archives. After this operation, 935 MB of additional disk space will be used. Get:1 http://us.archive.ubuntu.com/ubuntu bionic/main amd64 libsigsegv2 amd64 2.12-1 [14.7 kB] Get:2 https://packages.microsoft.com/ubuntu/16.04/mssql-server-2017 xenial/main amd64 mssql-server amd64 14.0.3076.1-2 [178 MB] Get:3 http://us.archive.ubuntu.com/ubuntu bionic/main amd64 gawk amd64 1:4.1.4+dfsg-1build1 [401 kB] Get:4 http://us.archive.ubuntu.com/ubuntu bionic-updates/main amd64 python2.7-minimal amd64 2.7.15~rc1-1ubuntu0.1 [1,304 kB] Get:5 http://us.archive.ubuntu.com/ubuntu bionic/main amd64 python-minimal amd64 2.7.15~rc1-1 [28.1 kB] Get:6 http://us.archive.ubuntu.com/ubuntu bionic-updates/main amd64 python2.7 amd64 2.7.15~rc1-1ubuntu0.1 [238 kB] Get:7 http://us.archive.ubuntu.com/ubuntu bionic/main amd64 libpython-stdlib amd64 2.7.15~rc1-1 [7,620 B] Get:8 http://us.archive.ubuntu.com/ubuntu bionic/main amd64 python amd64 2.7.15~rc1-1 [140 kB] Get:9 http://us.archive.ubuntu.com/ubuntu bionic/main amd64 libsasl2-modules-gssapi-mit amd64 2.1.27~101-g0780600+dfsg-3ubuntu2 [35.5 kB] Get:10 http://us.archive.ubuntu.com/ubuntu bionic/universe amd64 libc++abi1 amd64 6.0-2 [56.7 kB] Get:11 http://us.archive.ubuntu.com/ubuntu bionic/universe amd64 libc++1 amd64 6.0-2 [183 kB] Get:12 http://us.archive.ubuntu.com/ubuntu bionic/universe amd64 libjemalloc1 amd64 3.6.0-11 [82.4 kB] Get:13 http://us.archive.ubuntu.com/ubuntu bionic-updates/main amd64 libsss-nss-idmap0 amd64 1.16.1-1ubuntu1.2 [19.8 kB] 26% [2 mssql-server 15.5 MB/178 MB 9%] Fetched 180 MB in 7min 20s (409 kB/s) Preconfiguring packages ... Selecting previously unselected package libsigsegv2:amd64. (Reading database ... 194963 files and directories currently installed.) Preparing to unpack .../libsigsegv2_2.12-1_amd64.deb ... Unpacking libsigsegv2:amd64 (2.12-1) ... Setting up libsigsegv2:amd64 (2.12-1) ... Selecting previously unselected package gawk. (Reading database ... 194970 files and directories currently installed.) Preparing to unpack .../gawk_1%3a4.1.4+dfsg-1build1_amd64.deb ... Unpacking gawk (1:4.1.4+dfsg-1build1) ... Selecting previously unselected package python2.7-minimal. Preparing to unpack .../python2.7-minimal_2.7.15~rc1-1ubuntu0.1_amd64.deb ... Unpacking python2.7-minimal (2.7.15~rc1-1ubuntu0.1) ... Selecting previously unselected package python-minimal. Preparing to unpack .../python-minimal_2.7.15~rc1-1_amd64.deb ... Unpacking python-minimal (2.7.15~rc1-1) ... Selecting previously unselected package python2.7. Preparing to unpack .../python2.7_2.7.15~rc1-1ubuntu0.1_amd64.deb ... Unpacking python2.7 (2.7.15~rc1-1ubuntu0.1) ... Selecting previously unselected package libpython-stdlib:amd64. Preparing to unpack .../libpython-stdlib_2.7.15~rc1-1_amd64.deb ... Unpacking libpython-stdlib:amd64 (2.7.15~rc1-1) ... Setting up python2.7-minimal (2.7.15~rc1-1ubuntu0.1) ... Linking and byte-compiling packages for runtime python2.7... Setting up python-minimal (2.7.15~rc1-1) ... Selecting previously unselected package python. (Reading database ... 195173 files and directories currently installed.) Preparing to unpack .../0-python_2.7.15~rc1-1_amd64.deb ... Unpacking python (2.7.15~rc1-1) ... Selecting previously unselected package libsasl2-modules-gssapi-mit:amd64. Preparing to unpack .../1-libsasl2-modules-gssapi-mit_2.1.27~101-g0780600+dfsg-3ubuntu2_amd64.deb ... Unpacking libsasl2-modules-gssapi-mit:amd64 (2.1.27~101-g0780600+dfsg-3ubuntu2) ... Selecting previously unselected package libc++abi1:amd64. Preparing to unpack .../2-libc++abi1_6.0-2_amd64.deb ... Unpacking libc++abi1:amd64 (6.0-2) ... Selecting previously unselected package libc++1:amd64. Preparing to unpack .../3-libc++1_6.0-2_amd64.deb ... Unpacking libc++1:amd64 (6.0-2) ... Selecting previously unselected package libjemalloc1. Preparing to unpack .../4-libjemalloc1_3.6.0-11_amd64.deb ... Unpacking libjemalloc1 (3.6.0-11) ... Selecting previously unselected package libsss-nss-idmap0. Preparing to unpack .../5-libsss-nss-idmap0_1.16.1-1ubuntu1.2_amd64.deb ... Unpacking libsss-nss-idmap0 (1.16.1-1ubuntu1.2) ... Selecting previously unselected package mssql-server. Preparing to unpack .../6-mssql-server_14.0.3076.1-2_amd64.deb ... Unpacking mssql-server (14.0.3076.1-2) ... Setting up libc++abi1:amd64 (6.0-2) ... Setting up libsss-nss-idmap0 (1.16.1-1ubuntu1.2) ... Processing triggers for mime-support (3.60ubuntu1) ... Processing triggers for desktop-file-utils (0.23-1ubuntu3.18.04.2) ... Setting up libjemalloc1 (3.6.0-11) ... Setting up python2.7 (2.7.15~rc1-1ubuntu0.1) ... Setting up gawk (1:4.1.4+dfsg-1build1) ... Setting up libpython-stdlib:amd64 (2.7.15~rc1-1) ... Processing triggers for libc-bin (2.27-3ubuntu1) ... Processing triggers for man-db (2.8.3-2ubuntu0.1) ... Setting up libsasl2-modules-gssapi-mit:amd64 (2.1.27~101-g0780600+dfsg-3ubuntu2) ... Processing triggers for gnome-menus (3.13.3-11ubuntu1.1) ... Setting up python (2.7.15~rc1-1) ... Setting up libc++1:amd64 (6.0-2) ... Setting up mssql-server (14.0.3076.1-2) ... +--------------------------------------------------------------+ Please run 'sudo /opt/mssql/bin/mssql-conf setup' to complete the setup of Microsoft SQL Server +--------------------------------------------------------------+ SQL Server needs to be restarted in order to apply this setting. Please run 'systemctl restart mssql-server.service'. Processing triggers for libc-bin (2.27-3ubuntu1) ...
I then proceeded with steps to set the SA password and edition of SQL Server, to complete the installation successfully.
I hope you find this post useful. Please drop your comments below. Basit 🙂